This is a tool announcement and a build log. I built ShareSift because Snaffler's false positive rate is a real problem on engagements, and I wanted to see whether ML could fix it. The short answer is yes — but getting the evaluation right was harder than building the model.
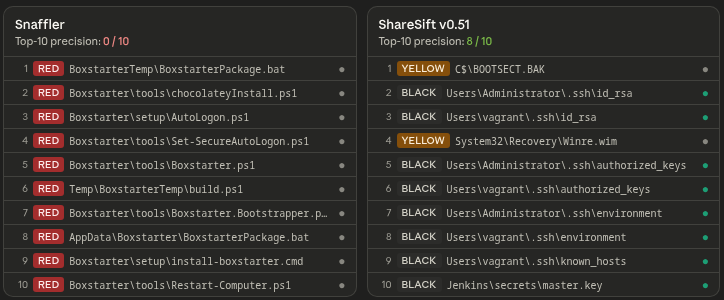
Snaffler hits 1,279 times. Seven are real.
If you've used Snaffler on an engagement, you know the drill. You run it against a share, get a wall of output, and spend the next hour triaging noise. Most of it is PowerShell scripts from public packages, tutorial code, parameter declarations — anything that contains the word "password" in any context.
Run Snaffler against Metasploitable 3 and it fires 1,279 times. About seven of those contain actual credentials. The other 1,272 are Boxstarter installer scripts.
The rule doing most of the damage is KeepPassOrKeyInCode. It fires 686 times on its own, on files like these:
# This fires KeepPassOrKeyInCode:
schtasks /CREATE ... /RP "$password" /XML "$taskFile"
# So does this:
.EXAMPLE PS C:\> Set-SecureAutoLogon -Password (Read-Host -AsSecureString)
# And this:
$script:BoxstarterPassword='$($script:BoxstarterPassword)'Snaffler's regex matches password="$variable" the same as password="Ok6/FqR5=". It doesn't inspect the right-hand side. That's not a bug — it's the hard limit of what regex can do here. Snaffler knows the file has "password" in it. It doesn't know whether that password is real.
Sort by Snaffler's own tier field and look at the first ten results. Top-10 precision is 0.000. You're reading Boxstarter tutorial code.
ShareSift's Top-10 precision on the same share: 0.800.
What ShareSift is
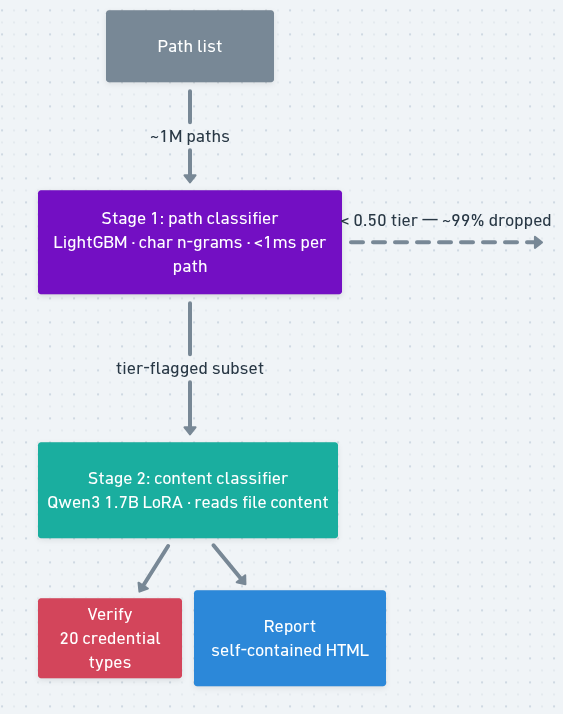
ShareSift is a two-stage ML pipeline for credential hunting in SMB file shares. It plugs into pysnaffler as a custom classifier and adds a path model and a content model on top. It also ships with live credential verification, an interactive HTML report, and a full engagement datastore designed for multi-day pentests.
Stage 1 is a LightGBM path classifier. It scores every path the share enumerator finds. Inference runs in under a millisecond. The artifact is 15MB and needs no GPU. Paths that score above a tier threshold get forwarded to Stage 2. Everything else gets dropped.
Stage 2 is a fine-tuned Qwen3 1.7B model. It reads the file content and returns a probability that the file contains a literal credential value — not a reference to one, not a mention of one, but an actual value someone could use. It only runs on paths Stage 1 flagged, typically a few hundred out of millions.
On content classification, ShareSift outperforms Wiz's published Llama recipe by 12.7 points in precision, 13.8 in recall, and 13.3 in F1. Those numbers are on ShareSift's own held-out test split, not a shared benchmark. On a neutral external benchmark — Samsung's CredData — a larger Mistral-7B recipe still beats ShareSift's best content classifier, so read the in-distribution win as a deployment result, not a state-of-the-art claim. I'll get to what that means later.
Why these models
LightGBM, not a transformer
I didn't start with LightGBM. The first instinct when building an ML layer for a security tool is to reach for a transformer. That was the wrong call for this task, and the ablations confirm it.
Paths are 20 to 80 characters of highly structured tokens: server names, share names, directory components, filenames, extensions. A large encoder's main advantages — long context, code-aware pretraining — are mostly wasted at this length. What matters is whether the model learns nonlinear interactions between features like extension, depth, directory keywords, and path shape.
I tested five configurations. P0 is the shipped model: char n-grams (3–5) plus 8 hand-crafted features, LightGBM, isotonic calibration. PR-AUC 0.9731.
Remove the hand features (P1) and PR-AUC drops 3.3 points. Remove the n-grams entirely and keep only hand features (P2) and PR-AUC drops 17.1 points — F1 collapses near zero. N-grams are the primary signal. Swap LightGBM for logistic regression on the same features (P3) and PR-AUC drops 4.1 points. The nonlinear interactions matter.
There's also a calibration wrinkle worth knowing about. Removing calibration (P4) actually improves raw F1 at the 0.5 threshold — but probability quality drops with it. The tier-band mapping (Black above 0.95, Red above 0.80, Yellow above 0.50) needs well-calibrated probabilities, not raw classification accuracy. Uncalibrated probabilities break the tiers.
The shipped model is the smallest thing that works at the quality level the tier bands require. It runs in under a millisecond per path and fits in 15MB. A transformer encoder would cost roughly 1,000× more per inference for no measurable gain on this task.
Qwen3 1.7B, not Llama
Wiz's April 2025 secrets-detection blog used a Llama 3.2 1B LoRA recipe. I replicated it on Qwen3 1.7B instead.
Distil Labs' 2025 SLM benchmark puts Qwen3 1.7B at 91.3% classification accuracy versus Llama 3.2 1B at 86.7%. Wiz's own pre-finetune numbers show Qwen at 143 tokens/sec versus Llama at 27. Wiz chose Llama because its pre-finetune recall was marginally higher. LoRA training closes that gap. Qwen3 is Apache-2.0 and has stronger code tokenization for the file-content distribution I'm classifying.
Fine-tuning used Unsloth at LoRA rank 16, alpha 32, 7 epochs, lr 2e-4, cosine schedule. The rank sweep confirmed 16 is the right size: rank 8 underfits by 3.5 points in F1, and ranks 32 and 64 match rank 16 without improving it.
Building the training data
No public dataset of SMB share paths with pentester-grade sensitivity labels exists. Corporate share topology is NDA-walled by nature — the paths that matter most on an engagement are the ones nobody publishes. I built training data from four sources.
Public corpus mining. GitHub Code Search, ServerFault, SuperUser, and Stack Overflow together have tens of millions of posts where real engineers reference real UNC paths in real scripts. I pulled 11,190 unique candidate paths using authenticated API access and per-query SHA256 caches for reproducibility. The Stack Overflow extraction required fixing a format bug mid-run: SO's 2024 data dump uses pipe-delimited tags instead of angle brackets, which caused the first 40-minute run to produce zero results.
Synthetic generation. Seven passes produced 1,851 records using ChatGPT, DeepSeek, and a local Qwen model. Getting useful synthetic data meant learning five rules the hard way.
Generate one class at a time. Ask for a "mix" and you get whatever ratio the model prefers — observed at roughly 20% positive, heavily skewed toward easy negatives. You have to set the ratio deliberately.
Supply server and share names. Left to its own, the model produced meridian-fs01 and corp-nas-02 for twenty consecutive paths. A model trained on two fictional server names learns those names as a signal. That's not useful.
Name every quality dimension explicitly. Mechanism variety only appeared when I demanded it. The model defaults to the easiest member of every class.
Use thinking mode only for hard negatives. For genuinely ambiguous paths — ones that would make a careful analyst pause — fast mode cheated by including folder names like Templates/ or Training/ that resolve the ambiguity. Thinking mode obeyed the constraint.
Regex-tier tokens are banned from the hard negative class. A synthetic negative containing id_rsa or .kdbx teaches the model to discount near-certain positives. The exclusion is enforced through the same callable the eval pipeline's contamination validator uses, so the list can't drift.
Labeling. A rule-based labeler cross-referenced Snaffler's TOML rules and Kingfisher's 942 detectors for baseline labels. Codex audited multiple passes. Combined agreement rate was 88%. The guidelines encode 14 sensitivity categories — from private_keys_x509 and ssh_credentials down to decoy_docs and benign_noise — with explicit tier criteria and boundary calls for ambiguous cases.
I caught my own data leak before publishing
Before writing up the results, I ran an integrity audit on the eval pipeline. It found a real problem.
The content classifier's test set had 43 records that leaked from training via cluster-level proximity. The splitting logic had partitioned by record, not by semantic cluster — records that were near-duplicates of training examples could appear in the test set and inflate measured performance. The original headline was "beats Wiz by 3–5 points on the held-out test set." That claim was real on its measurement, but the measurement was wrong.
The audit checked cross-split overlap at exact match and Jaccard similarity thresholds, training-to-test contamination at varying thresholds, and label source provenance.
| Severity | Before | After |
|---|---|---|
| Error | 2 | 0 |
| Warning | 3 | 0 |
The fix was a cluster-level splitter. Records in the same semantic cluster go entirely to train or entirely to test, never split across the boundary. Zero cross-split overlap at Jaccard 0.8, enforced at split time.
I retrained from scratch on the clean split and swept epoch count.
| Epochs | Precision | Recall | F1 |
|---|---|---|---|
| 3 | 0.816 | 0.820 | 0.818 |
| 5 | 0.978 | 0.926 | 0.951 |
| 7 (shipped) | 0.984 | 0.958 | 0.971 |
| 10 | 0.979 | 0.963 | 0.971 |
The 3-epoch result landed below the Wiz baseline (F1 0.818 vs 0.838). The leak had masked an undertraining problem — the model was getting bonus exposure to test records, making 3 epochs look sufficient when it wasn't. At 7 epochs on the clean split, the corrected headline: ShareSift beats Wiz's published baseline by 12.7 points in precision, 13.8 in recall, and 13.3 in F1, on ShareSift's own held-out test split. Better numbers, on a measurement that survives scrutiny.
The audit tooling, cluster-level splitter, and training contamination guard are all committed and reproducible. The training script refuses to start if the dataset path and test split path resolve to the same file. Every model output directory gets a training_metadata.json recording the training data SHA256, LoRA config, optimizer hyperparameters, seed, and timestamp — so anyone can verify provenance without re-running anything.
Testing rules without contaminating the test
The content classifier's data leak was a machine learning problem. But rule-based credential hunters have the same contamination problem — just hidden, because there's no explicit training set.
A rule author reads some examples, writes a regex, and validates against a benchmark drawn from the same pool of examples. The rule passes the benchmark because it memorizes it. Snaffler has 198 issues and PRs in its GitHub tracker representing five years of real operators filing "Snaffler missed X on a real engagement." Those issue threads are the closest free proxy for corporate SMB topology that doesn't require NDA access. The problem: if you use them both for rule authoring and for benchmarking, you've leaked the test set into training.
ShareSift's answer is a held-out discipline cycle. Before writing any rules that close the current generation's failures, I lock the next generation's test set from sources I haven't read yet. Rules shipped in v0.N can only reference sources that were locked at or before v0.(N-1). The just-locked generation's score is a snapshot of what the rules generalize to, not what they were trained on.
Four generations as of v0.51:
| Generation | Source PRs | Pre-rule baseline | Post-rule | Closed at |
|---|---|---|---|---|
| v1 | #78 Cisco, #135 FileZilla, #67 ADO | 36% | 100% | v0.49 |
| v2 | #198 CMD-set, #155 Azure CLI, #98 cred-filename, Chrome/Edge | 50% | 100% | v0.49 |
| v3 | #154 -password, #140 Kerberos, #139 MDE, #112 SCCM | 90%¹ | 100% | v0.50 |
| v4 | OPEN PRs #192 PPK, #186 SCCM-broad | 60%² | 70% | locked at v0.50 |
¹ v3's 90% baseline reflects pysnaffler bundling upstream rules from PRs #140 and #112. Not a strict generalization test.
² v4 uses open PRs that pysnaffler does NOT bundle — a tighter test.
The browser-creds rule at v0.48 is the clearest generalization signal. Snaffler issue #46 described Firefox logins.json. I wrote ShareSiftKeepFirefoxSavedCreds at v0.47 for Firefox. At v0.48 I generalized to a Chromium-base meta-rule covering any browser profile's Login Data SQLite. Held-out v2 — locked before the rule was authored — contained Chrome and Edge probes I had never written rules for. Both passed. The premise generalized from Firefox to four other browsers without any additional training.
None of the major rule-based credential hunters publish an equivalent. Snaffler is upfront about it: "like all good 'ML' projects, it just uses a shitload of if statements and regexen." No CHANGELOG metrics, no held-out set, no contamination discussion. TruffleHog, Gitleaks, Kingfisher, detect-secrets — none of them publish a per-version, per-generation recall scorecard with documented held-out splits. The concept of held-out testing is ML 101. Using it as a release discipline for a rule-based credential hunter appears to be new.
What a real corporate share looks like
The benchmarks above — GitHub-mined paths, Stack Exchange extractions, Metasploitable 3 — all share a limitation: they're constructed from public data or purpose-built labs. The most honest question about any credential hunter is "how does it perform on actual Windows NTFS share content?" Up to v0.50, the closest I had was an LLM-labeled 500-path synthetic benchmark. That number always came with a caveat.
v0.51 replaces the caveat with a real corpus.
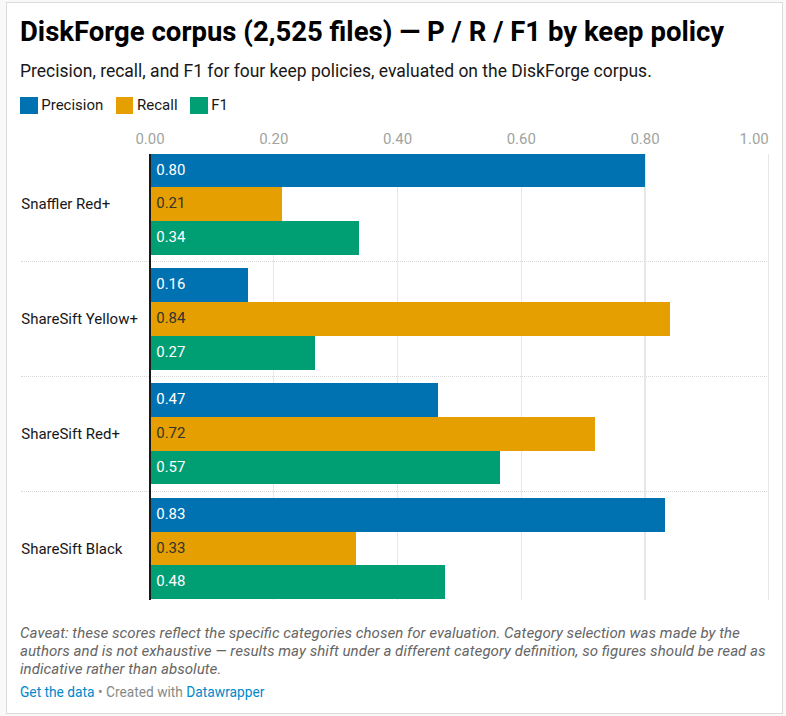
Using Stauffer's DiskForge, I built a 2525-file Windows NTFS partition: 75 synthetic-but-format-shaped credential files across 16 categories, mixed with 2420 realistic corporate-share noise files covering HR policies, finance reports, marketing assets, vendor PDFs, software install media, log archives, project source, and public templates. I added 20 precision-stress filenames designed specifically to trip credential-keyword rules — password_policy.docx, secrets_management_guidelines.pdf, and similar. The corpus is reproducible from a committed seed.
Same paths, same ground truth, both pipelines:
| Tool | Keep policy | P | R | F1 | Caught | Missed | FPs |
|---|---|---|---|---|---|---|---|
| Upstream Snaffler | Red+ | 0.800 | 0.213 | 0.337 | 16 | 59 | 4 |
| ShareSift v0.51 | Red+ | 0.466 | 0.720 | 0.565 | 54 | 21 | 62 |
| ShareSift v0.51 | Black-only | 0.833 | 0.333 | 0.476 | 25 | 50 | 5 |
At Red+ — the operator triage policy — ShareSift catches 3.4× more credentials than Snaffler (54 vs 16 of 75). The tradeoff is genuine: ShareSift surfaces 62 false positives versus Snaffler's 4. The FP volume is concentrated in binary-extension noise: .msi, .iso, and .psd files get probabilistic Yellow ratings from the path classifier. Document-shaped noise stays clean. If you want only findings you're certain about, Black-only gives 0.833 precision. If you don't want 59 real credentials missed silently, run Red+.
One honest caveat on these numbers. The 16 credential categories were authored to exercise every ShareSift rule generation from v0.46 to v0.50. Snaffler's defaults don't include rules for German credential filenames, CMD set "VAR=val", browser-creds meta-coverage, or several other patterns this corpus tests. A neutral-curated corpus would probably put Snaffler at 40–50% recall. The categories ShareSift covers are real corporate-share shapes — operator-reported in Snaffler's own issue tracker — so the operational gap is genuine. But category selection amplifies it.
Results on real shares
Metasploitable 3
1,054 enumerated paths. 40 verified ground-truth positives. Labels cross-checked by Opus and Codex with 93% agreement.
| Metric | Snaffler | ShareSift v0.51 |
|---|---|---|
| Recall | 97.5% (39/40) | 100% (40/40) |
| Top-10 precision | 0.000 | 0.800 |
| Top-20 precision | 0.000 | 0.450 |
Snaffler's 0.000 Top-10 precision is the default output sorted by Snaffler's own tier field — not a misconfiguration. The first hundred hits are Boxstarter PowerShell installer scripts firing on KeepPsCredentials. Even when you sort by Red tier, you still get tutorial noise before real credentials.
ShareSift's content classifier scored Boxstarter-style PowerShell at P(literal credential) = 0.122 and pushed it to the bottom of the ranked output. The classifier that distinguishes password="Ok6/FqR5=" from password="$password" is the wedge Snaffler's regex can't implement. I confirmed with a source grep across all of Snaffler's TOML rule files that there's no built-in suppression for Boxstarter-shaped false positives anywhere in the ruleset.
ShareSift also caught a Jenkins master.key that Snaffler's defaults missed — a genuine recall win from a blind-spot rule not in pysnaffler's bundled ruleset.
Metasploitable 2
The Linux story is starker. Snaffler's Windows-centric defaults catch 15 of 34 Linux credential files on MSF2 — 44.1% recall. ShareSift catches 34 of 34 — 100%. The gap is +55.9 percentage points. Every Snaffler catch is also a ShareSift catch. Snaffler catches nothing ShareSift misses.
The unique ShareSift catches are SSH host keys, authorized_keys files, sudoers, NFS exports, shadow file backups, Postfix config, raw MySQL user tables, and PHP config backups — credential surfaces that Snaffler's Windows-centric defaults don't cover. These came in through the v0.42 and v0.43 Linux rule expansion targeting the MSF2 gaps.
The full pipeline
Drop-on-Kali binary. Starting with v0.46, ShareSift ships as a 77MB single-file binary with zero Python prerequisites:
wget https://github.com/byevincent/ShareSift/releases/latest/download/sharesift
chmod +x sharesift
./sharesift --versionThe binary covers score-paths, scan-files, to-snaffler-tsv, sort, query, and export. The content classifier, SMB-direct, and live verification require the full Python install because they carry torch and smbprotocol.
SMB-direct scanning, no mount required. Point ShareSift at a UNC path with credentials and it walks the share over SMB2/3 directly. Auth flags follow netexec conventions:
# Password auth
uv run sharesift //10.10.10.5/Finance$ -u user -p pass
# Pass-the-hash
uv run sharesift //10.10.10.5/Finance$ -u CORP/user -H 'aad3b435b51404ee:27c4...'
# Kerberos from ticket cache
uv run sharesift //dc01.corp.local/SYSVOL$ -u alice -k --use-kcacheMulti-share batch scanning. Pipe netexec's share discovery into a single batch run:
nxc smb 10.10.10.0/24 -u user -p pass --shares | awk '/READ/{...}' > targets.txt
sharesift batch --targets targets.txt -u user -p pass --output-dir ./engagementEach target gets its own subdirectory. Per-target failures don't abort the batch. A batch_summary.jsonl records success and failure per target.
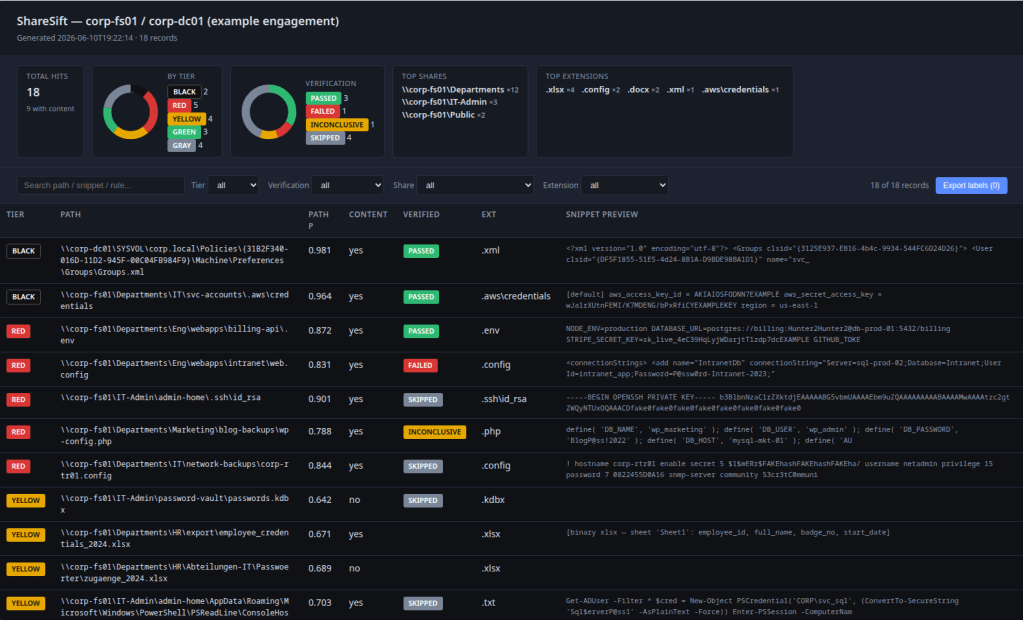
Live credential verification. sharesift verify checks credentials live against 20 verifier types: Anthropic, OpenAI, HuggingFace, GitHub, Slack, Databricks, AWS via STS GetCallerIdentity, GCP OAuth, Azure HMAC, SSH via paramiko bind, and SMB and LDAP dispatched automatically when structured parsers extract username/password pairs from files like web.config or kubeconfig. Status semantics match TruffleHog: passed, failed, inconclusive, skipped. Use --dry-run to see what would be verified without sending any traffic. A 3-second confirmation banner fires before live verification; suppress it with --no-banner for CI.
Engagement datastore. One engagement.db per pentest holds hosts, shares, files, and hits across multi-day runs in a SQLite schema designed for incremental crawl and resume. Query it directly:
sharesift query --db engagement.db --preset live-creds
sharesift query --db engagement.db --preset writable-shares
sharesift query --db engagement.db "SELECT host, COUNT(*) FROM hits GROUP BY host"Reporting and export. sharesift render-report generates a single self-contained HTML report with zero external dependencies — no CDN calls, works in air-gapped environments. Sortable columns, tier and verification status filters, full-text search, row expansion for extracted credential detail and per-verifier logs.
For delivery tools, sharesift export emits findings in Markdown, GhostWriter CSV, or SysReptor JSON:
sharesift export --db engagement.db --format ghostwriter --output findings.csv
sharesift export --db engagement.db --format sysreptor --output sysreptor.jsonActive learning. The report's expanded row has TP/FP/Discard buttons and a notes field. Labels persist across sessions and export as labels.jsonl. sharesift retrain-ranker joins those labels back to the original scan output and retrains a LightGBM ranker on path tier, path probability, content check result, and structured-parser confidence. Each engagement makes triage ordering better for the next one.
Structured parsers. Nineteen structured parsers cover the most common credential-bearing file types: .env, web.config, .aws/credentials, docker config.json, kubeconfig, terraform.tfstate, Ansible vault, Cisco running configs, Veeam config XML, KeePass databases, and more. Parsers extract typed fields rather than raw regex matches, giving the verify stage the pairing it needs for SMB and LDAP attempts.
Honest limitations
The Wiz comparison is on ShareSift's distribution, not a shared benchmark. The 13.3-point F1 delta is on ShareSift's held-out test split. On Samsung's CredData — an externally curated benchmark that neither model was designed for — ShareSift's best content classifier reaches F1 0.853. Biringa and Kul's Mistral-7B recipe reaches 0.985. The CredData numbers are the honest external comparison. The gap is mostly model size: Mistral-7B has 4× the parameters of Qwen3 1.7B, and ShareSift targets a single-consumer-GPU deployment.
The DiskForge benchmark reflects ShareSift's coverage choices. The 3.4× recall advantage over Snaffler is on a corpus built to exercise categories ShareSift specifically added rules for. A neutral-curated benchmark would put Snaffler closer to 40–50% recall. The categories are real (operator-reported in Snaffler's own tracker), but the gap is amplified by selection.
No real engagement validation. Every benchmark here uses public data or purpose-built labs. Metasploitable 3 is a teaching VM. DiskForge uses a synthetic NTFS image. ShareSift's performance on a real corporate target is directionally supported by the lab results, not directly measured.
Calibration holds in distribution. The tier-band precision contracts (Black above 0.95 means ~95% precision) are reliable on data from the same source as training. On out-of-distribution data, the Windows model's ECE rises from 0.007 to 0.30. Treat tier assignments as triage ordering, not probability contracts, when scanning real SMB shares.
Check your pysnaffler version. The Python port's bundled rule pickle lags the C# upstream. The GPP cpassword gap found during GOAD testing is one example. Verify rule coverage against the canonical Snaffler TOML files before you deploy.
Try it
ShareSift is open-sourced at https://github.com/byevincent/ShareSift. The quickest path to running it is the binary:
# Drop on Kali, no Python required
wget https://github.com/byevincent/ShareSift/releases/latest/download/sharesift
chmod +x sharesift
./sharesift --version
# Score paths from share enumeration
echo "\\\\dc01\\NETLOGON\\map.bat" | ./sharesift score-paths --stdinFor the full pipeline including SMB-direct and content scanning:
# Install with SMB-direct support
pipx install 'sharesift[smb]'
# One-shot scan of a remote share
sharesift //10.10.10.5/Finance$ -u user -p pass
# Or use individual stages for finer control
sharesift score-paths --input paths.txt --output scored.jsonl
sharesift scan-files --stdin --output hits.jsonl < paths.txt
sharesift verify --input hits.jsonl --output verified.jsonl --no-banner
sharesift render-report --input verified.jsonl --output report.htmlThe audit tooling, training scripts, eval benchmarks, and measurement infrastructure are all in the repo. Every number in this post is reproducible from committed code with pinned seeds. If a measurement doesn't hold up, open an issue.