I'd be bouncing between a browser, Splunk, course notes, Sigma rules, and old pentest writeups just to answer the same kinds of questions: Which Event IDs matter here? What does the SPL actually look like when it's not generic junk? Is this AD right exploitable or am I wasting time? The information was already in my notes. The problem was getting it back out fast enough to be useful.
So I built a local RAG pipeline around the stuff I actually use: course material, detection rules, gold-standard SPL queries, and pentesting procedures. Qwen3.5 35B-A3B through vLLM for generation, Qwen3-Embedding-0.6B for dense retrieval, ChromaDB, Whoosh for BM25, and Qwen3-Reranker-0.6B on top. Roughly 49,000 chunks in the index.
The basic tutorial version of RAG was nowhere near good enough for this domain. Cybersecurity retrieval breaks in ways that don't show up in generic demos. Sometimes the right answer is a detection with correct fields and pivots. Sometimes it's just an explanation.
The biggest lesson from this build was not about embeddings or model size. It was that bad corpus quality will crush everything downstream. I spent time on retrieval logic, reranking, query expansion, and routing. Deleting the bad data did more than all of that combined.

Why the normal RAG recipe fell apart here
The usual vector DB + top-k + LLM flow was a decent starting point, but it wasn’t enough for this domain.
A lot of the important artifacts in cybersecurity do not look like normal language. They're GUIDs, Event IDs, command flags, registry paths, API names, or ugly one-off strings that matter a lot and embed badly. DCSync is the obvious example. If the query says "DCSync" and the source only has replication GUIDs, dense retrieval can drift right past it while BM25 hits it instantly.
Intent is another problem. "What is LSASS?" and "Write a Splunk detection for LSASS dumping" should not go through the same pipeline. One wants explanation. The other wants fields, pivots, syntax, and something executable.
Then there's corpus quality. Once the index gets polluted, most of the clever tuning stops mattering nearly as much as people want it to.
What the pipeline turned into
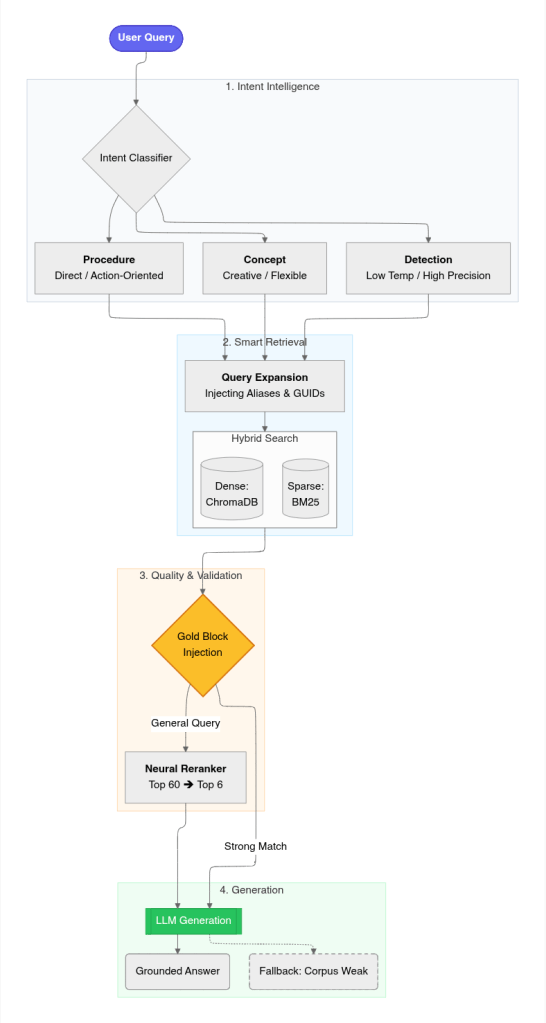
I didn't start with a five-stage pipeline because I had some grand design. I ended up there because the simpler versions kept breaking.
Query → Classify → Expand + Rewrite → Vector + BM25 → Gold Boost + Rerank → Qwen3 35B-A3BThe final shape was: classify the query, expand the query, run hybrid retrieval, jam any known-good gold blocks into the context if the query clearly matches them, rerank the pile, then generate. That sounds neat written out like that, but each piece only exists because I got burned by not having it. Query classification exists because conceptual questions and detection questions were poisoning each other. Expansion exists because one attack can show up as a nickname, an API name, a command, or a GUID. Gold boost exists because if I already have a validated SPL block for DCSync, I don't want cosine similarity deciding whether I see it today.
I couldn’t get away with dense retrieval alone. It was fine when the query was broad, but the moment a question hinged on exact junk like a GUID, a flag, or a tool name, BM25 was the part that kept the system honest. “Scheduled task lateral movement” could still surface ATExec, but detection queries lived or died on exact tokens, so I pushed the weighting toward BM25.
One small thing that mattered way more than it should have: the embedding instruction prefix. It had to match at query time and index time. If it drifted, the embedding space quietly went crooked and nothing looked obviously broken. Those were some of the easiest failures to miss because nothing looked obviously broken.
# hybrid_query.py — Embedding setup
# Qwen3-Embedding-0.6B · BF16 · CUDA
# BF16 on Blackwell (sm120). TF32 for matmul throughput.
_PREFERRED_TORCH_DTYPE = torch.bfloat16
torch.backends.cuda.matmul.allow_tf32 = True
EMBED_MODEL = "/home/george-5090/models/qwen3-embedding-0.6b"
EMBED_DIM = 1024
# Instruction prefix for asymmetric retrieval.
# Must match the prefix used at index time — or embedding space geometry breaks.
QUERY_INSTRUCTION = """Instruct: Given a question, retrieve relevant passages that answer it.
Query: """Same story with temperature. At 0.7, the system would produce nice-looking SPL that was just wrong in subtle ways: hallucinated fields, bad Event IDs, fake confidence. Dropping factual queries down to 0.3 was one of the highest-leverage changes I made. It didn't stop hallucinations, it just made them less polished and easier to catch.
Query Expansion
Adversary technique names are inconsistent across any real corpus. "DCSync" appears as dcsync, lsadump::dcsync, IDL_DRSGetNCChanges, GetNCChanges, and the raw GUIDs 1131f6aa and 1131f6ad — all referring to the same underlying attack. A query containing only "dcsync" misses documents using the API-level terminology.
The expansion layer handles this through YAML-loadable rules. Each rule defines trigger phrases and a set of needle terms injected into the retrieval query. The DCSync rule alone injects 12 alternates, covering Mimikatz command syntax, DS-Replication API names, and the specific GUIDs for both "Get-Changes" and "Get-Changes-All" permissions. Rules are configurable at runtime without touching the codebase.
The Gold Standard Boost
Raw retrieval could get me into the right area, but it still missed the best answer too often. For the high-confidence detection cases, that wasn't good enough.
For detection engineering queries, there is a curated file of validated SPL blocks covering specific techniques — DCSync, Kerberoasting, LSASS dumping, ADCS abuse, Pass-the-Hash, and about 100 others. These need to surface deterministically when the query matches, not probabilistically based on cosine similarity.
The gold boost function runs artifact signature matching against the query before the main retrieval pass. Signatures are defined as groups of indicator terms. For DCSync: one group contains ["event id 4662", "eventcode=4662"], another contains the replication GUIDs, another contains ["drsuapi", "getncchanges", "secretsdump"]. If enough groups match, the corresponding gold record is injected directly to the top of the context window, bypassing the scoring pipeline.
If the query is clearly DCSync, I want the best DCSync block in the context every time.
The gold sections file uses two-pass indexing: Tool: field aliases first (high confidence), then body-text scan for any unclaimed aliases. This prevents a single block from being claimed by multiple overlapping aliases during startup.
The Reranker
After hybrid retrieval produces 60 candidate chunks, Qwen3-Reranker-0.6B scores each query-document pair. This is a generative reranker that produces relevance scores by extracting the logit difference between "yes" and "no" tokens from the causal language model, not a CrossEncoder with a classification head. It runs in batches of 16 and returns the top 6 of 60 candidates.
# hybrid_query.py — Qwen3-Reranker yes/no logit extraction
# Generative reranker: P(yes | query, document)
# Extracts probability from the yes/no token logits
self.token_true_id = tokenizer.convert_tokens_to_ids("yes")
self.token_false_id = tokenizer.convert_tokens_to_ids("no")
scores = torch.softmax(
logits[:, [self.token_true_id, self.token_false_id]], dim=-1
)[:, 0] # P(yes)This stage consistently recovers chunks that ranked poorly on cosine similarity but are genuinely the best answer — a common failure mode when the query phrasing diverges from the document's vocabulary.
Where it broke
Here’s where the system broke.
The first one was the dual pipeline split. I had two separate retrieval/generation paths in process_query(). One path ran the actual RAG flow. The other kicked in when folder filters were selected, bypassed the reranker, called generate_response() with is_rag=False, and even told the model to fall back to its own knowledge when context was weak. In other words, the normal workflow was silently steering people into the broken path. I wasn't just getting bad answers. I had built a hallucination lane and wired it into the UI.
Another one was pure math, which somehow made it worse. ChromaDB was returning cosine distance in [0,2], and I treated it like similarity. The conversion in the code was wrong. No crash, no warning, just rankings that looked believable enough to trust until you stared at them long enough. Every score downstream was off.
Then there was the WEBSCRAPED mess, which was the real nightmare. I had about 20,000 low-quality web-scraped chunks in the index. When I sanity-checked queries like AS-REP roasting with Impacket, DCSync with Mimikatz, and Kerberoasting with GetUserSPNs.py, the top result for all three was the same useless Pupy C2 article. Then I checked the similarities and realized it was sitting in basically the same band for everything — including "Python programming tutorial" and even "weather forecast." At that point it was obvious what had happened: the instruction prefix had compressed a huge chunk of the corpus into the same fuzzy similarity blob, and the WEBSCRAPED folder was winning purely because there were 20,000 chances for mediocrity to float to the top. I deleted it. That fix did more than half the clever retrieval work combined.
The reranker config pointed to a directory that didn’t exist. That meant the reranker never loaded, and the system silently fell back to raw retrieval order. I fixed the path and added a startup health check so that kind of failure would be obvious immediately.
I also had the reranker wired through the wrong inference path at first. I treated Qwen3-Reranker-0.6B like a CrossEncoder. It isn't one. It's a causal LM doing yes/no logic extraction. That one only surfaced because I finally sat down with the model card and tested known-good query/document pairs instead of assuming the wrapper class was fine.
The retry logic was another self-inflicted problem. I had it set to retry when the model said things like “I don’t have” or “I cannot find,” which is exactly what it should say when the context is insufficient. The retry path then re-ran generation without context, which turned a correct refusal into a fabricated answer. I cut it back so retry only fires on structurally busted output.
One thing that surprised me: raw course notes retrieved fine and still produced weaker answers than the gold-formatted records. Same general content, very different output quality. Once I gave the model structured fields like command, flags, prerequisites, expected output, and OPSEC notes, the answers got sharper fast. That wasn't some abstract embedding issue. The structure itself was doing work.
The query that made the improvement obvious
The cleanest before-and-after test was DCSync detection with Windows Security logs.
Earlier in the project, that query was returning the wrong kind of context entirely. I’d ask for DCSync and get back top hits like Pupy C2, CyberGate RAT strings, Cobalt Strike malleable profiles, NetSupport, and Empire instead of anything tied to replication abuse. The resulting SPL looked plausible on the surface, but it was missing the core pieces: correct Event IDs, replication GUIDs, and source grounding.
After the fixes, the same query finally started returning the kind of answer I wanted. The gold block fired, the DCSync GUIDs were there, the reranker was actually doing its job, and the output included EventCode 4662, the replication properties, the 4624/4672 pivot, MITRE mapping, and tuning notes that sounded like they came from somebody who had actually worked the detection.
How I tested it, and where it still lies
I tested it with twelve queries. Eight were in the lane I actually built this for: detection engineering and AD pentesting. Four were there on purpose to expose the edge of the system.
The in-scope set did well enough that I’d actually use the system. DCSync detection was strong, Kerberoasting held up, and LSASS dump detection via comsvcs.dll came back clean. Golden Ticket was mostly right, though the TicketEncryptionType handling was a little brittle, and AS-REP roasting plus hashcat syntax also landed well. ESC8 was decent, GenericAll pathing was mostly right, and the delegation answers were solid enough that this is the part of the project I trust.
The out-of-scope or weak areas were more useful than the good scores. NetSupport artifacts were partial. The Volatility 3 process injection question fell apart because the corpus had lecture-style prose instead of command-first material. And one abstract detection prompt about "blending into normal traffic" got answered with a technically decent NTDS shadow-copy detection — vssadmin, diskshadow, ntdsutil, ESENT event codes — that had almost nothing to do with the actual question. That kind of miss is dangerous because it looks competent at a glance.
The most annoying hallucination in the whole set was the GenericAll answer expanding RBCD to "Remote Bitlocker Key Disclosure." The actual abuse logic after that was still mostly right. That kind of failure is what makes these systems hard to trust at a glance.
What mattered more than the score was where the system still failed. When the corpus is strong and the query stays inside the lane I tuned for, the system is useful. Outside that lane, it can still produce polished nonsense.
What Still Needs Work
The Whoosh side still has a stale-index problem. If I update the corpus and skip the rebuild step, BM25 can quietly serve old state with no obvious warning. That's not a hard bug to understand, but it's the kind that wastes time because the system doesn't look broken.
The multi-turn state handling is still a single-user hack. Right now the session-state FSM is just a global dictionary. Fine on a local box. Bad idea anywhere else.
The <think>...</think> cleanup also annoys me. It works, but I'm handling it with regex in the app layer when it really belongs in the serving layer. Any time you're regex-stripping model output after the fact, you're admitting part of the stack is in the wrong place.
And the procedural coverage gate still isn't tight enough. The Volatility question should have been blocked instead of dressed up with generic prose. If the retrieved material doesn't contain command syntax, paths, or real procedural signals, I want the system to stop pretending otherwise.
What I trust now is that I know where the system helps and where it starts bluffing. That's a better place to be than having a model that sounds polished and gives you no clue when it's making things up.